【原创】ElasticSearch 分页重复的问题
相关环境
ElasticSearch 6.7.0
Python 3.7
Python Elasticsearch Library 7.9.0
问题描述
当使用 Elasticsearch 进行分页取数时,出现了跨页数据重复的问题。
问题原因
这是由于 ES 的分片存储与分片检索机制导致的数据重复,具体可参与下面信息。
https://www.elastic.co/guide/cn/elasticsearch/guide/current/_add-an-index.html
https://www.cnblogs.com/xsht/articles/5286510.html
解决方法
参考 stackoverflow 上面的方法解决了此问题
https://stackoverflow.com/questions/10836142/elasticsearch-duplicate-results-with-paging/30241658
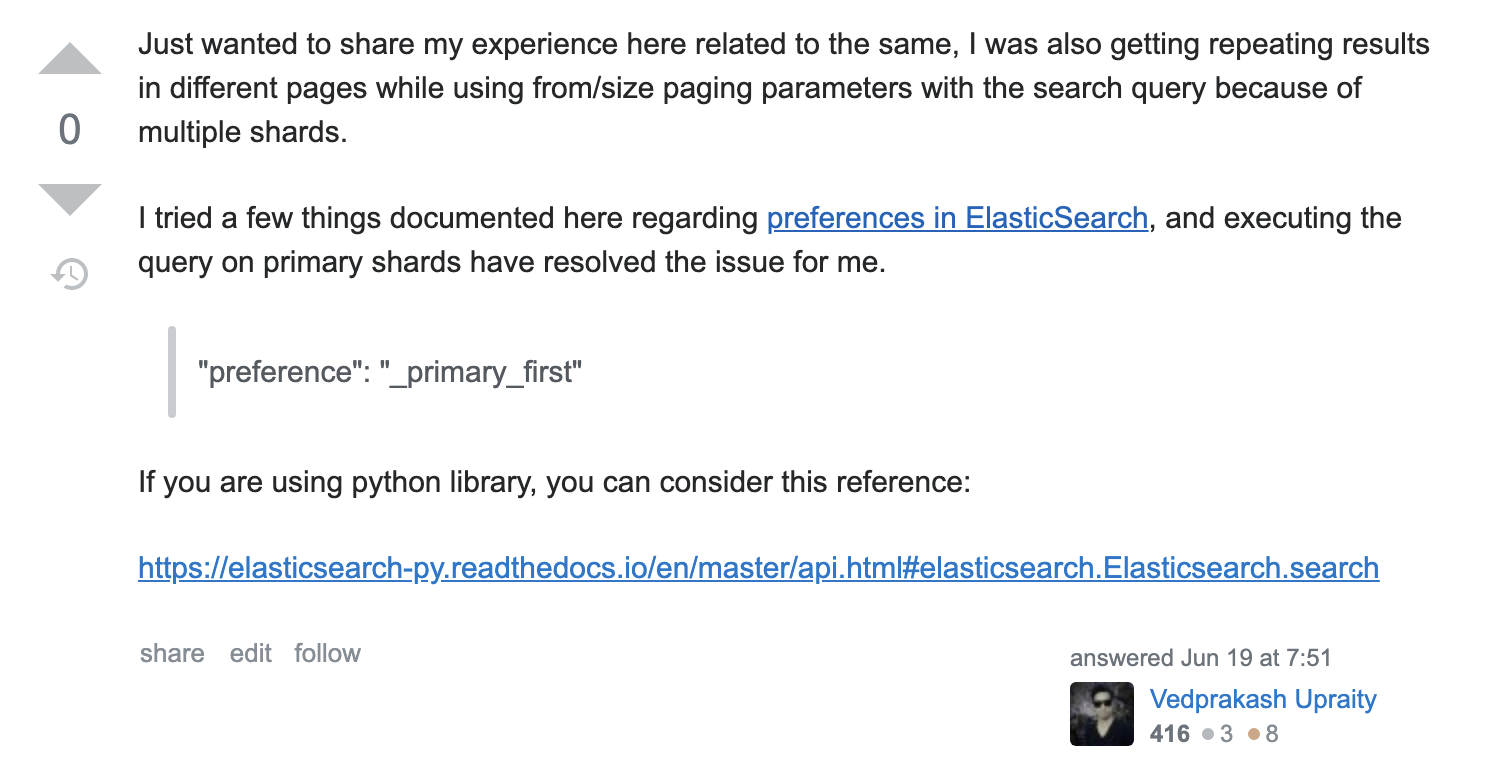
代码片断:
res = es.search(index=index,
doc_type=doc_type,
body=query,
search_type="dfs_query_then_fetch",
scroll="5m",
preference="_primary_first"
)
注:
elasticsearch 中的 _primary_first 参数从 6.1 版本以后过时了,7.0 版本之后则会移除,可以使用 _only_nodes 或者 _prefer_nodes 参数代替。
/Users/jiangzhuolin/PycharmProjects/es_demo/venv/lib/python3.7/site-packages/elasticsearch/connection/base.py:190: ElasticsearchDeprecationWarning: [_primary_first] has been deprecated in 6.1+, and will be removed in 7.0; use [_only_nodes] or [_prefer_nodes]
warnings.warn(message, category=ElasticsearchDeprecationWarning)
附录
完整代码示例:
# -*- coding:utf-8 -*-
from elasticsearch import Elasticsearch
# ES cluster domain
domain = "jiangzl.tpddns.cn"
# ES index name
test_index = 'test_index'
# ES type name
test_type = 'test_type'
query = {
"query":
{"term": {"name": "test"}},
"size": 100
}
# elasticsearch cluster hosts list
hosts = ["%s:9201/" % domain, "%s:9202/" % domain, "%s:9203/" % domain]
# creating elasticsearch connection object
es = Elasticsearch(hosts=hosts,
sniffer_timeout=60,
timeout=5,
retry_on_timeout=True,
max_retries=5
)
def _scroll_search_v1(index, doc_type, query):
res = es.search(index=index,
doc_type=doc_type,
body=query,
search_type="dfs_query_then_fetch",
scroll="5m",
preference="_primary_first"
)
return res
if __name__ == '__main__':
# 模拟 15 页的请求
for pageNo in range(1, 16):
scroll_res = _scroll_search_v1(test_index, test_type, query)
hits = scroll_res.get('hits')
page = 1
while page < pageNo and hits.get("hits"):
page += 1
# 使用 scroll 来滚动获取
scroll_res = es.scroll({'scroll': '5m', 'scroll_id': scroll_res.get('_scroll_id')})
hits = scroll_res.get('hits')
for hit in hits.get('hits'):
print("page:\t%s\tid:\t%s" % (pageNo, hit['_source']['id']))
相关参考:
https://stackoverflow.com/questions/10836142/elasticsearch-duplicate-results-with-paging/30241658
https://stackoverflow.com/questions/39270182/how-to-query-a-specific-shard-for-a-document
https://www.elastic.co/guide/en/elasticsearch/reference/6.8/search-request-preference.html#search-request-preference

近期评论